Hace algunos días, un compañero
de trabajo tenía la necesidad de actualizar los datos de varias tablas a través
de SSIS: cada tabla tenía la misma estructura que las otras y los nombres de
las tablas estaban almacenados en otra tabla, entonces lo que pensé fue en recorrer
el contenido de la tabla donde se encontraban los nombres y construir la cadena
mediante una expresión de otra variable más.
Es posible que existan otras soluciones, aquí les dejo lo que hice:
-- CREANDO LA TABLA QUE CONTIENE LOS NOMBRES DE LAS TABLAS IF OBJECT_ID( 'dbo.catTablas' ) IS NOT NULL DROP TABLE dbo.catTablas; GO CREATE TABLE dbo.catTablas( cve INT IDENTITY( 1,1 ) , nombreTabla VARCHAR(50) ) GO -- CREANDO LAS TABLAS QUE SERAN MODIFICADAS POSTERIORMENTE IF OBJECT_ID( 'dbo.tabla1') IS NOT NULL DROP TABLE dbo.tabla1; GO CREATE TABLE dbo.tabla1( cve INT IDENTITY( 1,1 ) , descripcion VARCHAR(50) ); GO IF OBJECT_ID( 'dbo.tabla2') IS NOT NULL DROP TABLE dbo.tabla2; GO CREATE TABLE dbo.tabla2( cve INT IDENTITY( 1,1 ) , descripcion VARCHAR(50) ); GO IF OBJECT_ID( 'dbo.tabla3') IS NOT NULL DROP TABLE dbo.tabla3; GO CREATE TABLE dbo.tabla3( cve INT IDENTITY( 1,1 ) , descripcion VARCHAR(50) ); GO IF OBJECT_ID( 'dbo.tabla4') IS NOT NULL DROP TABLE dbo.tabla4; GO CREATE TABLE dbo.tabla4( cve INT IDENTITY( 1,1 ) , descripcion VARCHAR(50) ); GO IF OBJECT_ID( 'dbo.tabla5') IS NOT NULL DROP TABLE dbo.tabla5; GO CREATE TABLE dbo.tabla5( cve INT IDENTITY( 1,1 ) , descripcion VARCHAR(50) ); GO -- INSERTANDO LOS NOMBRES DE LAS TABLAS INSERT INTO dbo.catTablas VALUES( 'dbo.tabla1') , ( 'dbo.tabla2'), ( 'dbo.tabla3') , ( 'dbo.tabla4') , ( 'dbo.tabla5') GO -- INSERTANDO ALGUNOS DATOS EN LAS TABLAS INSERT INTO dbo.tabla1 VALUES( 'descripcion de la cve 1 de la tabla 1' ) , ( 'descripcion de la cve 2 de la tabla 1' ); GO INSERT INTO dbo.tabla2 VALUES( 'descripcion de la cve 2 de la tabla 2' ) , ( 'descripcion de la cve 2 de la tabla 2' ); GO INSERT INTO dbo.tabla3 VALUES( 'descripcion de la cve 1 de la tabla 3' ) , ( 'descripcion de la cve 2 de la tabla 3' ); GO INSERT INTO dbo.tabla4 VALUES( 'descripcion de la cve 1 de la tabla 4' ) , ( 'descripcion de la cve 2 de la tabla 4' ); GO INSERT INTO dbo.tabla5 VALUES( 'descripcion de la cve 1 de la tabla 5' ) , ( 'descripcion de la cve 2 de la tabla 5' ); GO -- CONSULTANDO EL RESULTADO SELECT * FROM dbo.catTablas; SELECT * FROM dbo.tabla1; SELECT * FROM dbo.tabla2; SELECT * FROM dbo.tabla3; SELECT * FROM dbo.tabla4; SELECT * FROM dbo.tabla5;
Una vez que hayan ejecutado el script anterior, procederemos a crear
un nuevo paquete DTSx y crearemos algunas variables, para esto necesitaremos 1
variable para almacenar el resultado de la consulta a nuestra tabla que
contiene los nombres de las otras tablas, 1 variable para construir la cadena
SQL y, para el ejemplo, necesitaremos otras 2 variables más para almacenar el
contenido de las columnas, este número depende de la cantidad de columnas que
necesiten o que devuelva la consulta inicial:


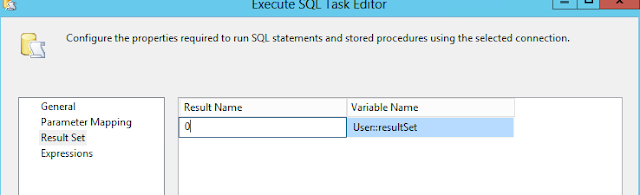
En la opción de la izquierda en Result Name escribimos 0 y en Variable Name elegimos el nombre de nuestra variable donde almacenaremos el resultado de la consulta en este caso User::resultSet
A continuación, arrastramos un objeto Foreach Loop Container y unimos el flujo desde el previo Execute SQL Task, damos doble click y en la opción Collection, en la propiedad Enumerator seleccionamos Foreach ADO Enumerator, después en ADO object source variable seleccionamos nuestra variable de tipo object y además seleccionamos Rows in the first table como la siguiente imagen:

Ahora en nuestra área de trabajo, arrastramos un objeto EXECUTE SQL TASK donde lo
configuraremos de la siguiente manera: En la opción General seleccionamos Full
Result Set, en Connection Type escogemos
el tipo de conexión que hayamos creado en este caso ADO.NET y en Connection el
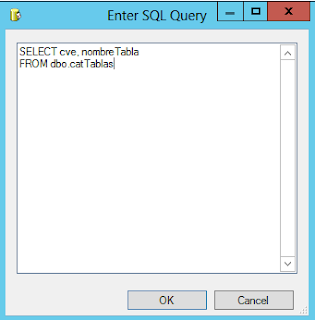
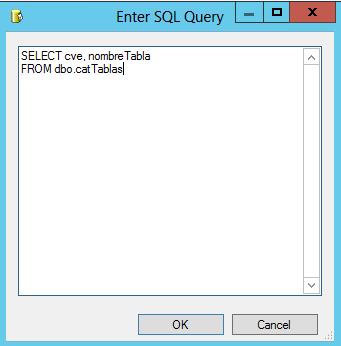
nombre de nuestra conexión y SQLStatement
introducimos nuestro query en este caso SELECT cve, nombreTabla FROM
dbo.catTablas

En la opción de la izquierda en Result Name escribimos 0 y en Variable Name elegimos el nombre de nuestra variable donde almacenaremos el resultado de la consulta en este caso User::resultSet

A continuación, arrastramos un objeto Foreach Loop Container y unimos el flujo desde el previo Execute SQL Task, damos doble click y en la opción Collection, en la propiedad Enumerator seleccionamos Foreach ADO Enumerator, después en ADO object source variable seleccionamos nuestra variable de tipo object y además seleccionamos Rows in the first table como la siguiente imagen:

Nos vamos a la opción Variable Mappings de nuestro Foreach Loop Container y agregaremos nuestras variables que almacenaran el contenido de las columnas de nuestra consulta contenida en la variable User::resultSet, para el ejemplo son User::cve y User::nombreTabla, además es necesario especificar el orden en el que aparecen en la consulta empezando con 0 como el inicial, veamos la imagen:

Hemos terminado con este control, damos aceptar y vamos ahora a la ventana propiedades de la variable strSQL, para poder verla basta presionar F4 o click en el menú VIEW -> Properties Window, en la expresión debemos agregar nuestra consulta que deseamos en este caso realizaré un UPDATE, damos click en el botón con los 3 puntos decimales en la propiedad Expression de la variable y nos aparecerá el Expression Builder y escribiremos nuestra consulta:


Ahora
ya tenemos nuestra consulta para actualizar el contenido de las tablas,
generada a partir de otra tabla que contiene los nombres de dichas tablas a
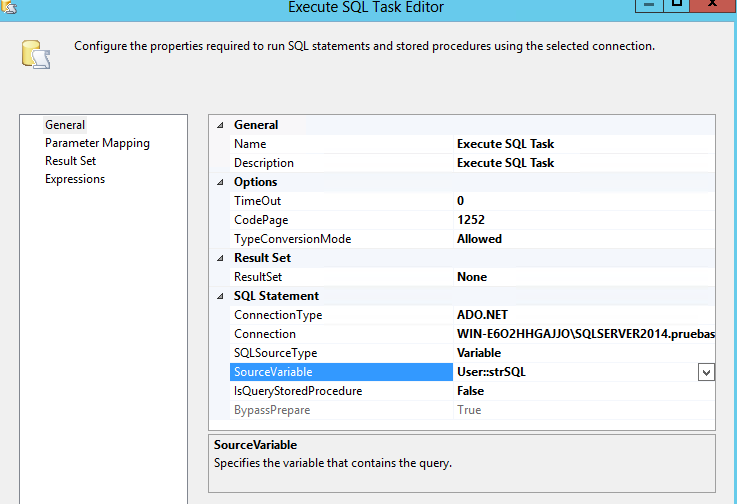
modificar, solo falta ejecutar la cadena SQL con un Execute SQL Task, configuremoslo de la siguiente manera: Propiedad
ResultSet -> None, SQLSourceType -> Variable, SourceVariable ->
User::strSQL, y las propiedades de nuestra conexión.
Nuestro paquete quedaría más o menos así:

Solo hace
falta ejecutarlo y vean el resultado.
Si tienen
alguna duda al respecto, no olviden que existe la parte de los comentarios o el
formulario de contacto, les responderé tan pronto me sea posible.
SALUDOS
COMPARTE ESTA INFORMACION SI TE PARECIO INTERESANTE




0 comentarios:
Publicar un comentario